Evaluate any robot policy, and generate the data behind it
Manifold runs any policy on any benchmark and ranks it on a shared leaderboard. Stardust generates the sensor-true synthetic data that trains the perception underneath. One pipeline, from training data to reproducible evaluation.
Open source. 1,000 rollouts per run. Any simulator.
Robots pass in the lab and fail in the field
A policy that clears 90% of test cases in the lab still fails far more often in the real world, because real test sets are small, static, and impossible to stage at scale. You cannot evaluate against the long tail of objects, grasps, lighting, and clutter that actually breaks a policy.
Bifrost closes both ends of that loop. Train perception on Stardust synthetic data that covers the long tail, then evaluate the trained policy on Manifold across every benchmark, at thousands of rollouts, with failure analysis you can act on. Evaluation leads, because you cannot improve what you cannot measure.
Evaluation is the bottleneck
// evaluating robots today
- ✕A single sim eval rollout still takes 24 hours or more, and every benchmark needs a hand-built harness
- ✕Every policy and every benchmark has a different shape, so every lab rebuilds the harness from scratch and the work never compounds
- ✕Reproducibility is informal: no shared leaderboard, no CI, no citable run
- ✕Real-world test sets are broken, and there is no systematic way to evaluate robots at scale
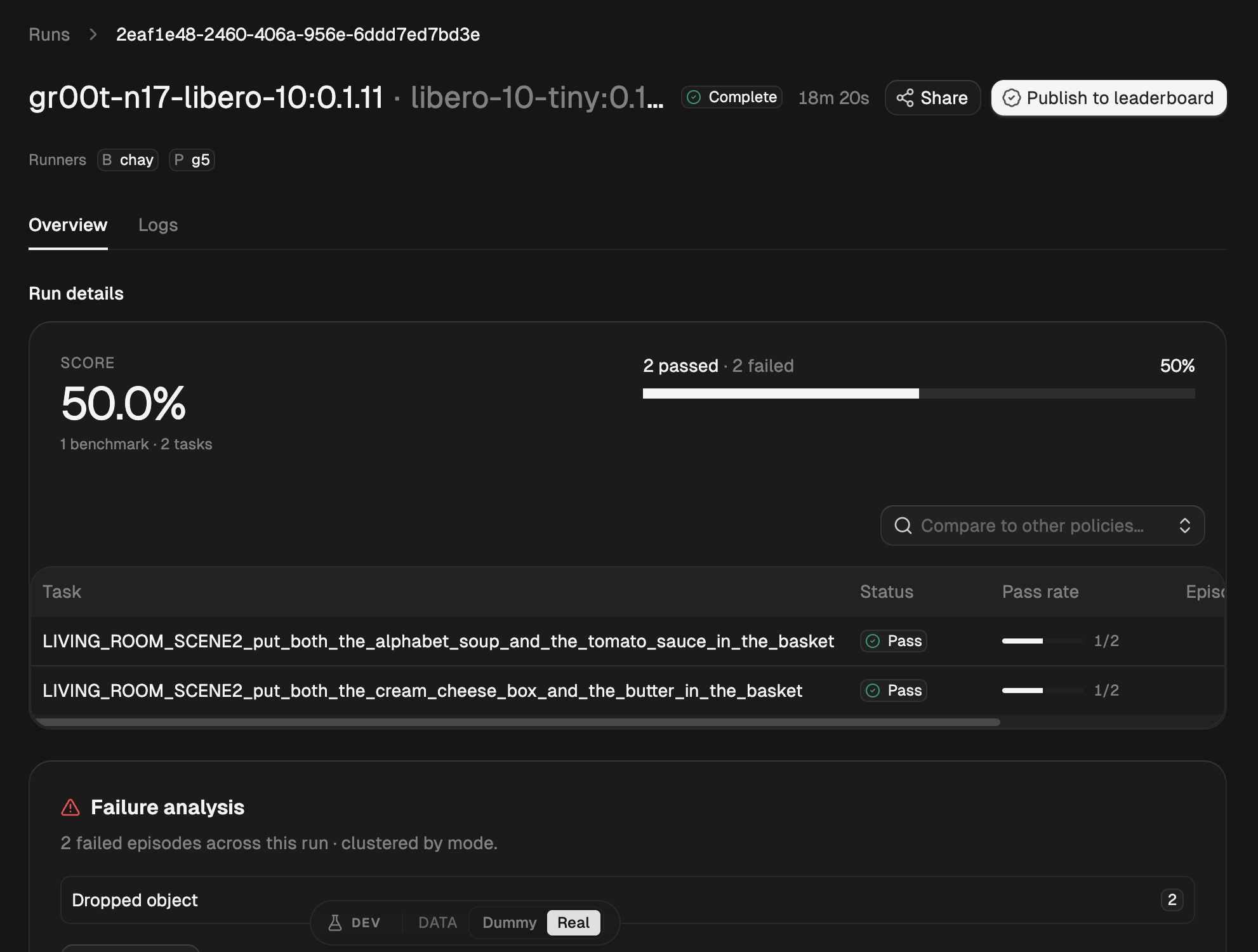
Drop in your policy, run millions of evaluations, see exactly where it fails
Manifold is the open-source orchestration layer for robot evaluation. Any policy should run on any benchmark, scaled to a thousand rollouts, without re-engineering the harness.
And the perception data behind the policy
Manifold and Stardust, in action
What teams build with it
Speaks your domain
The vocabulary, sensors, and benchmarks robotics teams actually use.
Built with the teams setting the bar in robotics and mobility.
Questions teams ask
How do you evaluate a VLA policy?
Drop the policy into Manifold and run it across any benchmark, LIBERO, RoboCasa, Isaac Lab, or MuJoCo, at thousands of rollouts. You get success rate plus per-task and per-step failure modes live, and a reproducible run you can cite.
What is sim-to-real for manipulation?
It is the test of whether a policy that works in simulation holds up on real hardware. Manifold quantifies the gap, and Stardust narrows it with sensor-true synthetic training data.
How do you run thousands of robot eval rollouts?
Manifold parallelizes rollouts across thousands of GPU instances in one line, turning an overnight job into a lunch break.
Can I add CI to my robot policy training?
Yes. Hook Manifold into your pipeline and every checkpoint is evaluated automatically, so regressions surface before they ship.
Why use synthetic data if you already have real data?
Real data gives you more of the same distribution. Synthetic data stress-tests the conditions you never captured and shows which real data to collect next. In one detection benchmark, synthetic-trained models hit 95.9% F1 versus 48.7% for real.
Put your policy on the board
Tell us what you are building and the scenarios you need. We will get you access.