Evaluate any policy on any benchmark, in one click
Open-source policy evaluation for robotics and autonomy. Run any policy on any benchmark, scale to a thousand rollouts with one command, and compare on a shared leaderboard.
Evaluation is the bottleneck
// evaluation today
- ✕A single eval rollout still takes 24 hours or more
- ✕Every policy and every benchmark has a different shape, so every lab rebuilds the harness from scratch
- ✕Reproducibility is informal. No shared leaderboard, no CI
Any policy should run on any benchmark, scaled to a thousand rollouts, without re-engineering the harness.
From one command to a ranked result
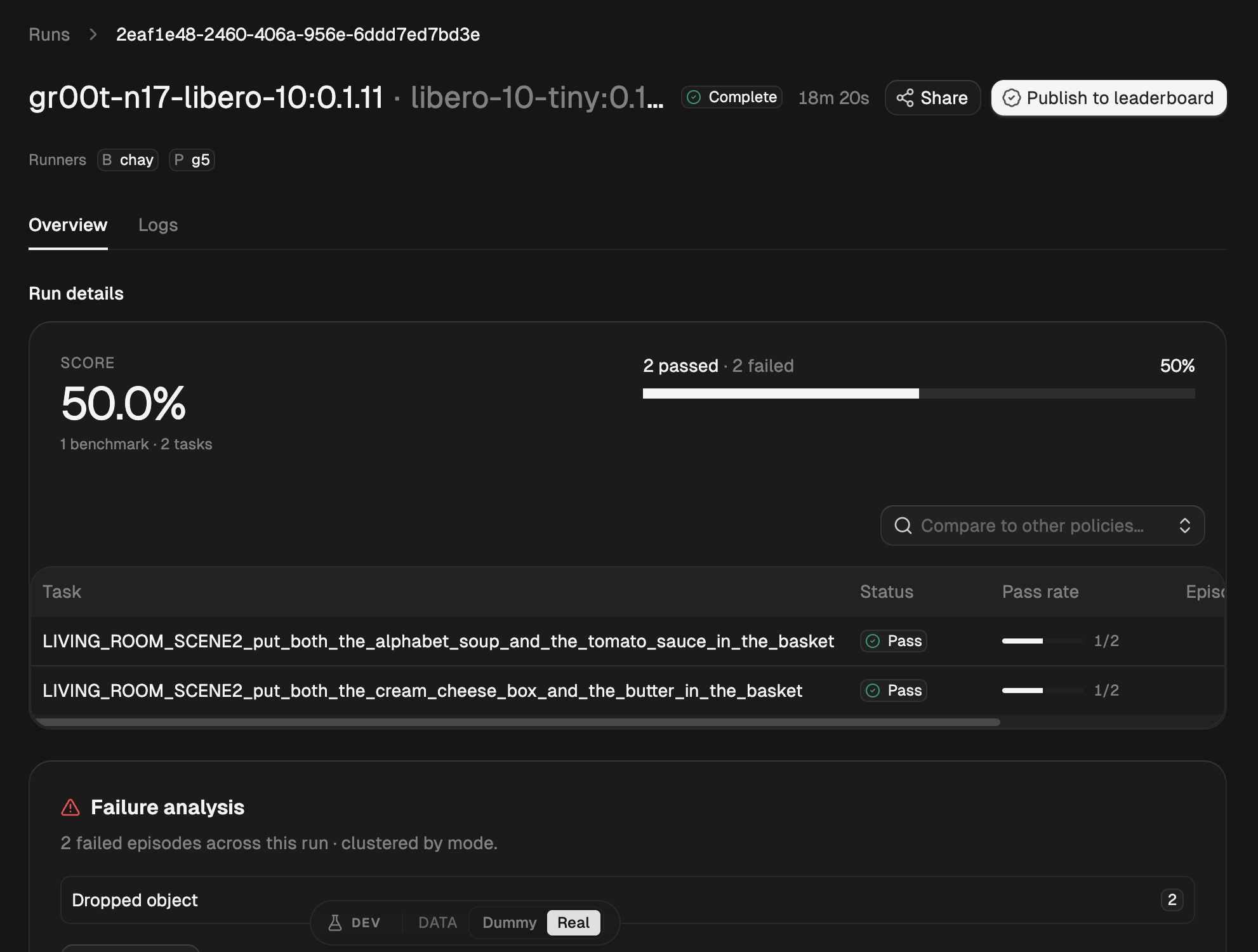
Live run detail from manifold.bifrost.ai: score, per-task pass rates, and clustered failure modes.
- LIBERO
- LIBERO-90
- RoboCasa
- RoboCasa-kitchen
- your own scenarios
- Manipulation
- Dexterity
- Humanoids next
- One click, any benchmark. LIBERO, RoboCasa, or your own scenarios.
- Scale on demand. A thousand rollouts from a single CLI command.
- Live leaderboard. A standard the field can point to, not a snapshot.
- Open source. Runner, harness, and leaderboard schema are all open.
Built to be open
The standards layer for physical AI evaluation cannot be proprietary. Manifold's runner, harness, and leaderboard schema are all open source, so results compound across the field instead of dying in a Notion doc.
Isaac Sim / Isaac Lab substrate · free GPU credits for researchers via our cloud partner · open-sourcing soon.
Set the standard for physical AI
Manifold is open source and free to run. Star the repo, run your first eval, and put your policy on the board.